Pugetbench
Nuke “special project”
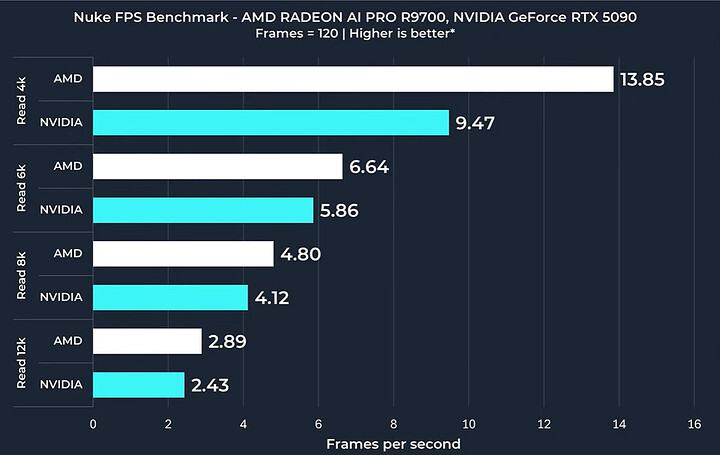
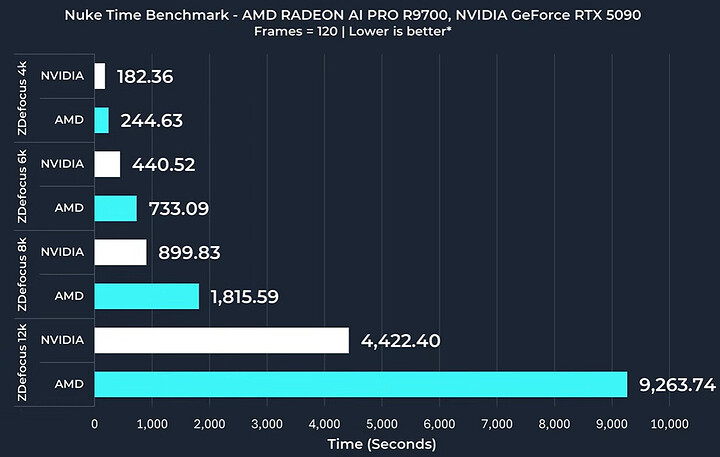
GPU của AMD hoạt động tốt ở đây cho đến khi gặp phải một giới hạn tính toán nào đó trong bài kiểm tra 'Defocus' phức tạp hơn.
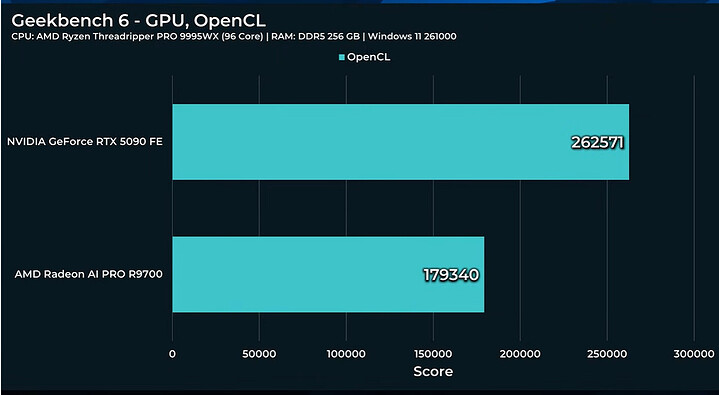
Như thường lệ, các bài kiểm tra hiệu năng tổng hợp cho thấy Nvidia vượt trội hơn hẳn. Đối với AI, cấu hình 2x R9700 có thể khá nhanh trên Windows, với nền tảng Vulkan.
.png)
Nhờ những thay đổi trong tuần trước, tôi không cần phải làm nhiều việc đặc biệt cho ComfyUI và ROCm. Hướng dẫn của chúng tôi ở đây.
Minisforum MS S1 Max Comfy UI Guide 78 nó vẫn có thể hoạt động tốt trên 9070XT hoặc R9700 Pro. Hơn 150 token/giây với tất cả các núm điều chỉnh và chốt chặn được kéo ra hết cỡ.
Trong một bài đánh giá khác của HOSTKEY
Việc thử nghiệm từng card đồ họa NVIDIA một có thể trở nên nhàm chán, đặc biệt là khi sự khác biệt giữa các thế hệ gần đây chủ yếu nằm ở sức mạnh của bộ xử lý dòng Blackwell, dung lượng bộ nhớ và độ rộng bus. Tuy nhiên, sẽ thú vị hơn khi xem các đối thủ cạnh tranh có gì để cung cấp, đặc biệt là khi họ mạnh dạn gắn nhãn các tính năng này là "AI".
Hôm nay, chúng ta sẽ thử nghiệm card đồ họa AMD Radeon AI Pro R9700 với 32 gigabyte bộ nhớ video. Đây là card đồ họa chuyên nghiệp đầu tiên của AMD được thiết kế đặc biệt để tăng tốc cục bộ trí tuệ nhân tạo (AI) trên máy trạm. Nó không phải là một card truyền thống dành cho dựng hình 3D hoặc các tác vụ CAD (như dòng Radeon PRO W); mà nó đại diện cho một loại sản phẩm mới: “bộ tăng tốc AI cho hệ thống máy tính để bàn”. Mặc dù, về thông số kỹ thuật phần cứng, về cơ bản nó giống với Radeon RX 9070 XT, vì cả hai card đều sử dụng cùng một chip Navi 48 với 64 đơn vị tính toán (CU) và 4.096 bộ xử lý luồng. Tuy nhiên, Radeon AI Pro R9700 có dung lượng bộ nhớ gấp đôi (và tất nhiên, giá cao hơn).
Khám phá bên trong động cơ
Thông số kỹ thuật của GPU này được liệt kê trong bảng bên dưới. Chúng ta cũng sẽ so sánh trực tiếp các tính năng của nó với thế hệ GPU NVIDIA trước đó, cụ thể là RTX A5000 với 24GB bộ nhớ, cũng như dòng Blackwell, được đại diện bởi RTX PRO 4000 với 24GB bộ nhớ.
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Như có thể thấy, mặc dù GPU mới của AMD được sản xuất bằng quy trình tiên tiến hơn, nhưng nó sử dụng bộ nhớ GDDR6 và có mức tiêu thụ điện năng cao nhất trong ba mẫu. Tuy nhiên, nó cũng có thêm 16 GB bộ nhớ video và giá thành thấp hơn.
Thử nghiệm thẻ trong thực tế
Để thử nghiệm, hai máy chủ đã được sử dụng: một máy có cấu hình mạnh hơn với bộ xử lý AMD Ryzen 9 7950X (4.5GHz, 16 lõi), 128GB bộ nhớ DDR5 và 1TB SSD NVMe; máy còn lại có cấu hình yếu hơn, được trang bị bộ xử lý Core i9-9900K (5.0GHz, 8 lõi), 64GB bộ nhớ DDR5 và cũng 1TB SSD NVMe. Nói thẳng ra, nền tảng đầu tiên cho kết quả tốt hơn, đặc biệt là trong các tác vụ phụ thuộc nhiều vào CPU hoặc yêu cầu tải nhanh các tệp lớn từ SSD. Trong thử nghiệm GPU, sự khác biệt giữa hai nền tảng là dưới 1%.
Thật tiếc là chúng tôi không chụp được ảnh của cấu hình đầu tiên (sử dụng bộ xử lý EPYC); tuy nhiên, chúng tôi sẽ cho các bạn xem cấu hình thứ hai. Cả hai máy chủ đều được lắp ráp trong khung máy tùy chỉnh do chúng tôi phát triển, có thể xếp chồng ba tầng trên giá đỡ, chiếm 3U không gian. Chúng tôi sẽ cung cấp thêm chi tiết về các khung máy này trong các bài viết sắp tới.
Dưới đây là hình ảnh thực tế của card đồ họa do Sapphire sản xuất.



Như bạn thấy, đây là card đồ họa hai khe cắm với hệ thống làm mát được thiết kế xung quanh một quạt/tuabin duy nhất, tương tự như hệ thống làm mát mà Nvidia sử dụng cho các GPU chuyên nghiệp của họ.
Giờ đến phần kiểm tra.
Trước tiên, chúng ta cần làm cho card hoạt động đúng cách. Chúng tôi đã sử dụng Ubuntu 24.04 làm hệ điều hành, vì card này chỉ có thể được cấu hình đúng cách trên các phiên bản kernel 6.13 trở lên; do đó, chúng tôi cần nhánh phân phối Linux chính thức, vốn không có sẵn cho Ubuntu 22.04. Cuối cùng, chúng tôi đã thành công trong việc làm cho card hoạt động với phiên bản kernel 6.18.2 (chúng tôi đã thử nghiệm vào cuối năm ngoái). Như thường lệ, chúng tôi đã cung cấp hướng dẫn chi tiết về cách thực hiện việc này, cũng như một tập lệnh cài đặt đặc biệt (cũng được bao gồm trong tài liệu); bạn chỉ cần sao chép tập lệnh đó, chạy nó từ tài khoản root trong dòng lệnh và nó sẽ xử lý tất cả các thiết lập cần thiết cho bạn. Mục tiêu chính của chúng tôi là chạy ROCm trên card, nhưng chúng tôi cũng đã thử nghiệm hiệu năng của nó trong việc kết xuất 3D bằng cách sử dụng khung HIP.
Nếu mọi thứ diễn ra suôn sẻ với bạn (giống như với chúng tôi), thì lệnh amd-smi (nó có gợi nhớ đến điều gì không?…) sẽ cung cấp cho bạn kết quả tương tự. Ảnh chụp màn hình đầu tiên hiển thị hiệu năng trên bộ xử lý EPYC (được thể hiện bằng sự hiện diện của thành phần liên quan đến AMD thứ hai trong ảnh chụp màn hình), và ảnh chụp màn hình thứ hai hiển thị hiệu năng trên bộ xử lý i9. Trong cả hai trường hợp, chúng tôi đều sử dụng ROCm phiên bản 7.1.1.
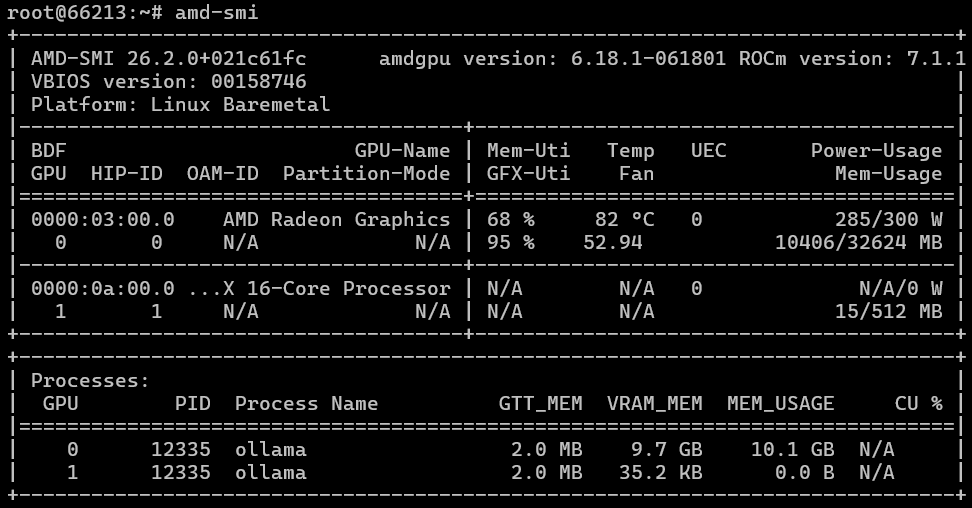
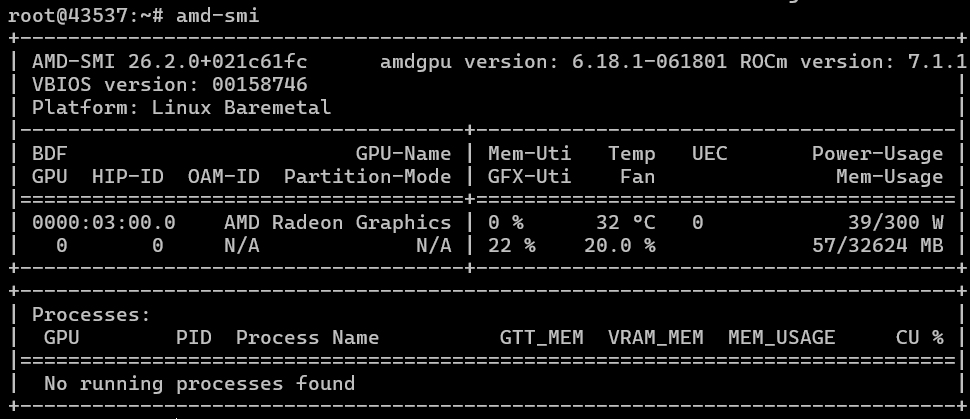
Tiếp theo, chúng tôi phải phát triển thêm bài kiểm tra AI dựa trên Ollama để đảm bảo nó có thể hoạt động và xuất thông tin từ GPU của AMD. Chúng tôi đã chạy thử nghiệm bằng nhiều mô hình khác nhau (trong trường hợp của chúng tôi, DeepSeek R1 và gpt-oss:20b) và thu được các kết quả sau:
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Như bảng số liệu cho thấy, hiệu năng của các GPU này tương đương với NVIDIA RTX A5000 (lưu ý rằng RTX A5000 thậm chí không chạy trên bus PCI tốc độ cao). Hơn nữa, các GPU mạnh hơn từ dòng “Green” của AMD, sử dụng cùng dung lượng bộ nhớ video (ngay cả các mẫu dành cho người tiêu dùng), lại vượt trội hơn dòng “Red” của NVIDIA gần ba lần.
Bạn có thể tìm thấy bảng so sánh đầy đủ các GPU tại đây .
Mặt khác, sự hỗ trợ cho ROCm đang bắt đầu khá hứa hẹn. Trong một số trường hợp, nó thậm chí còn vượt trội hơn cả CUDA; tuy nhiên, với CUDA, đôi khi chúng ta vẫn phải dựa vào các bản dựng hàng đêm của PyTorch và các công cụ tương tự.
Còn đối với các nhiệm vụ khác thì sao?
Theo truyền thống thử nghiệm của chúng tôi , chúng tôi sẽ thử hiển thị đồ họa và video trong ComfyUI. Sử dụng mô hình Z-image Turbo, với độ phân giải 1024x1024… và một thử nghiệm nhanh với chủ đề “gấu”.
"Ảnh tư liệu chân thực chụp bên trong một tổ hải ly trên một hồ nước yên tĩnh vào ban đêm: ba con hải ly đang đóng vai kỹ sư CNTT, lắp ráp một máy chủ 19 inch vào một giá đỡ nhỏ. Mỗi con hải ly đội một chiếc mũ bảo hiểm màu vàng tươi với logo HOSTKEY rõ nét, sắc sảo, dễ đọc được in ở phía trước (chính xác là: “HOSTKEY”, viết hoa), nằm ở giữa, độ tương phản cao, chữ rõ ràng, không bị méo mó. Một con hải ly giữ các thanh ray của giá đỡ, một con khác cắm cáp vá RJ-45 vào bộ chuyển mạch mạng, con thứ ba kiểm tra đèn LED trạng thái trên bảng điều khiển phía trước. Ánh sáng đèn vonfram ấm áp, nội thất gỗ ấm cúng, kết cấu lông ướt chân thực với những giọt nước nhỏ li ti, vân gỗ sống động, hơi nước thoang thoảng từ bộ lông ẩm ướt, hình ảnh phản chiếu của hồ nước có thể nhìn thấy qua một cửa sổ nhỏ. Một chồng dây buộc cáp gọn gàng, một chiếc tua vít nhỏ và một chiếc máy tính xách tay hiển thị màn hình terminal trên một chiếc bàn gỗ. Ánh sáng điện ảnh nhưng chân thực, độ sâu trường ảnh nông, nhiếp ảnh tài liệu 35mm, khẩu độ f/2.0, ISO 800, lấy nét sắc nét vào những con hải ly, mũ bảo hiểm và giá đỡ máy chủ, độ chi tiết cao, màu sắc tự nhiên, phản chiếu chân thực, không có vẻ hoạt hình, không có hiệu ứng CGI."

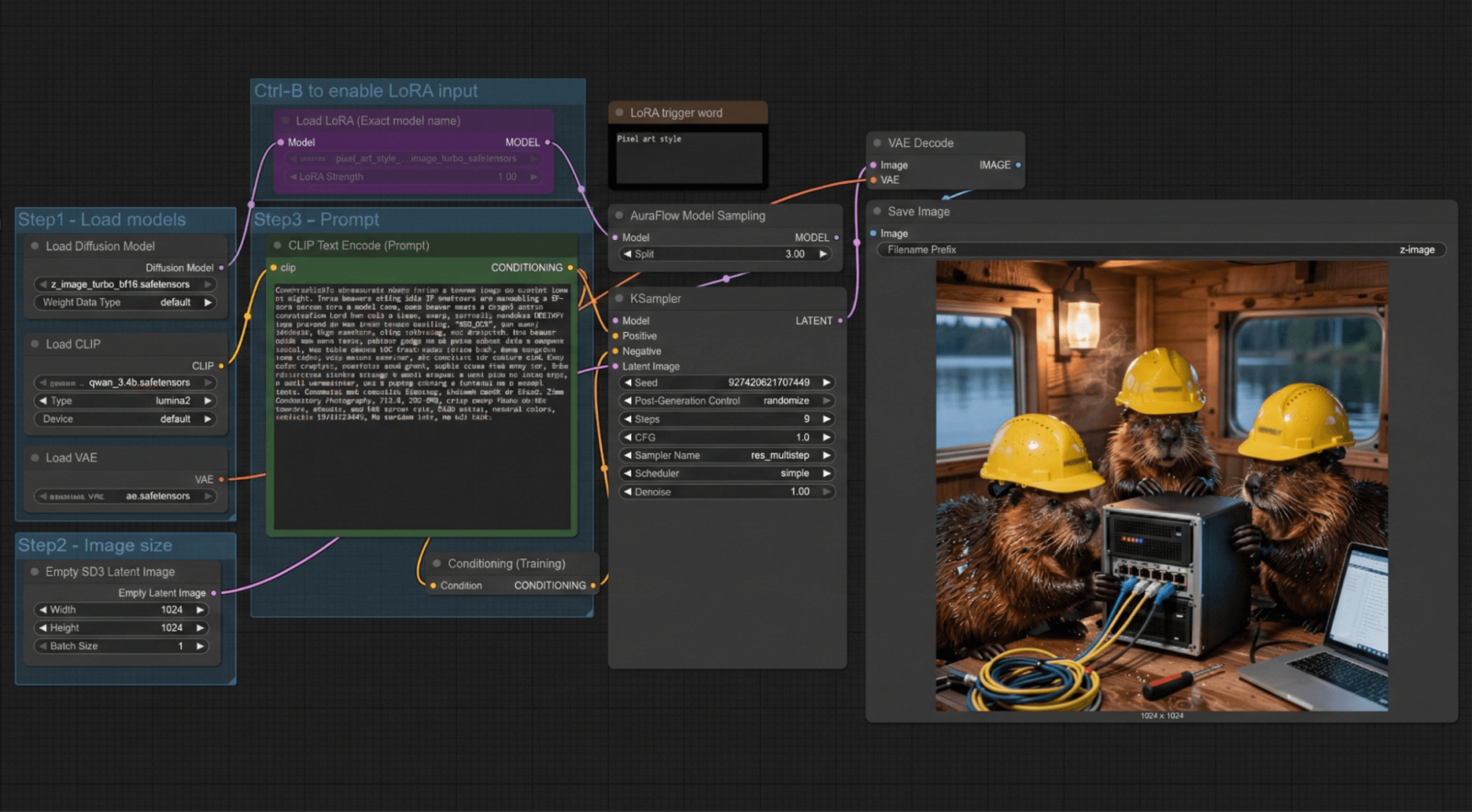
Quá trình tạo ảnh mất 6-7 giây, với tổng thời gian là 14-15 giây ngay cả khi độ phân giải được tăng lên HD. Để so sánh, RTX PRO 2000 mất 26 giây cho toàn bộ quá trình và 14 giây chỉ riêng cho giai đoạn tạo ảnh. Đáng tiếc là chúng tôi chưa từng thực hiện các bài kiểm tra tạo ảnh trên các card đồ họa khác của mình trước đây.
Đối với Kandinsky 5 Lite, khi sử dụng chế độ “văn bản trong video” với cùng chủ đề, chế độ này sẽ tạo ra tải trọng tối đa cho card đồ họa, tiêu thụ từ 280 đến 300 watt điện năng.
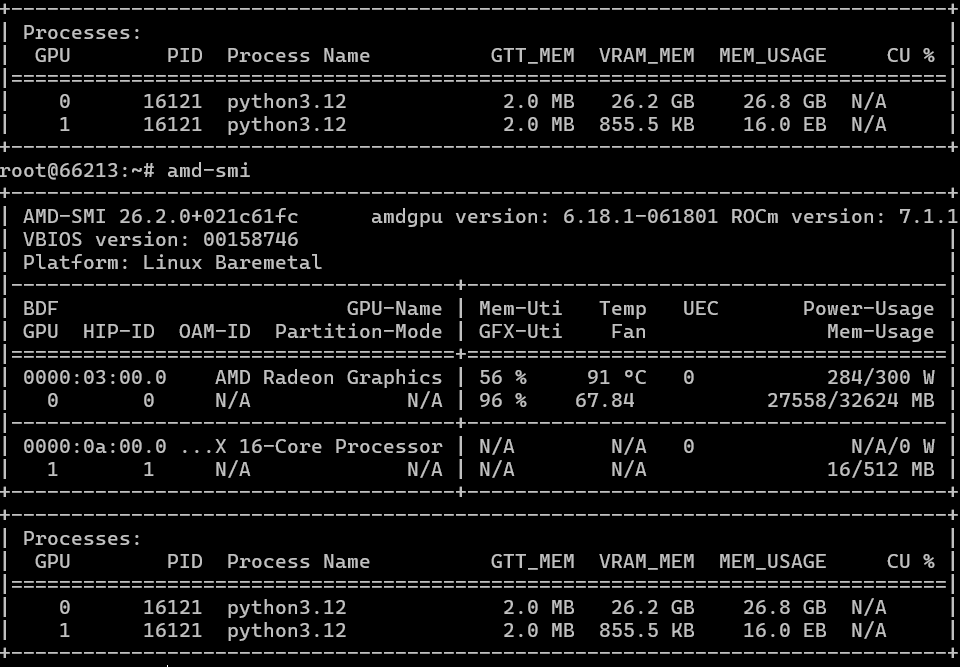

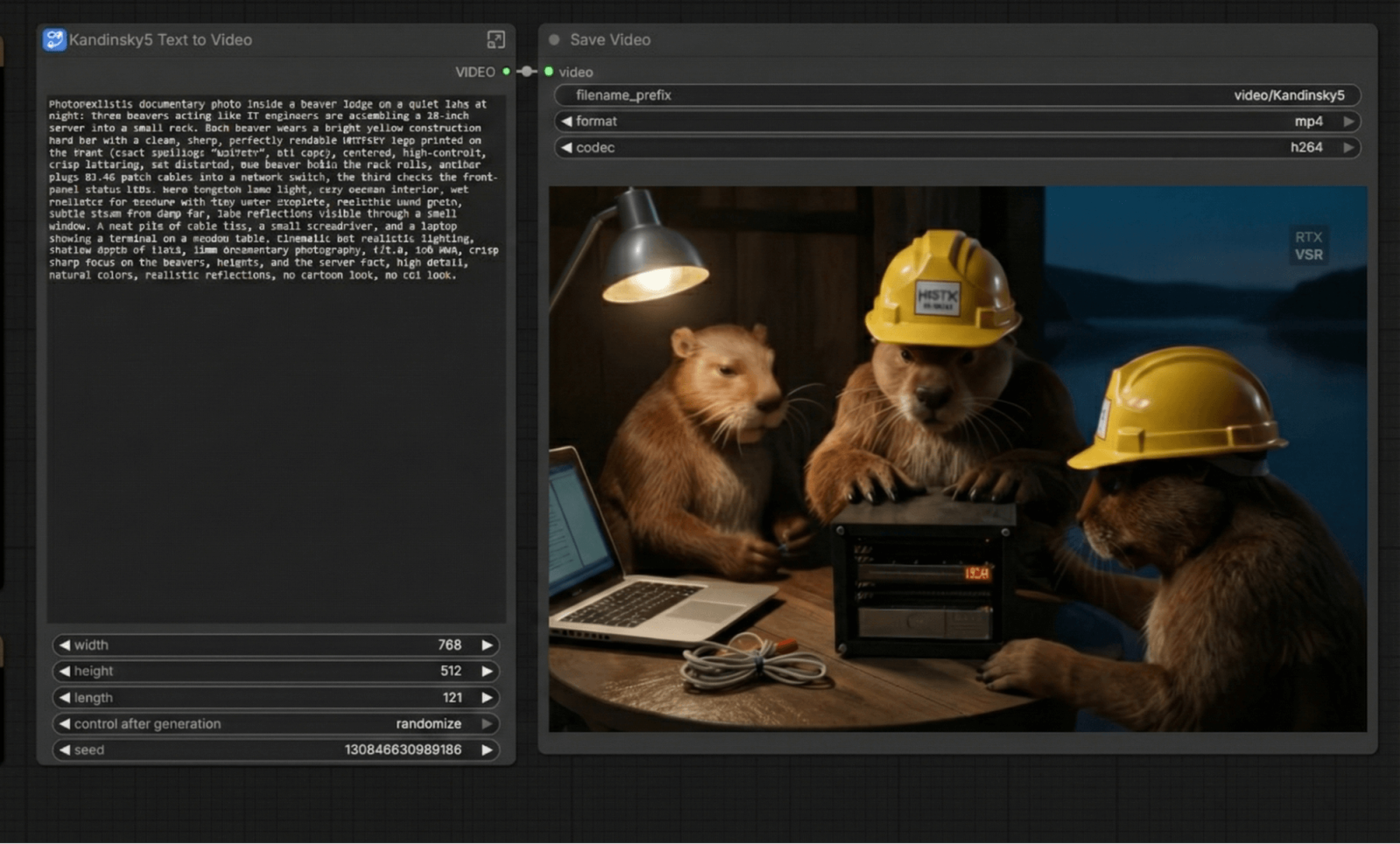
Tóm lại, quá trình này mất 24 phút. Card đồ họa NVIDIA RTX PRO 2000 cũng mất 24 phút. Điều này có nghĩa là khi tạo video, "đội đỏ" (những người sử dụng phương pháp tối ưu hóa kém hiệu quả hơn) bị giảm hiệu năng đáng kể. Trước đây, trong các phiên bản mới nhất của nhánh ROCm 6, hiệu năng tạo video đã giảm 30%, và có thể vấn đề này cũng đã chuyển sang nhánh 7. Tuy nhiên, trong trường hợp này, nỗ lực tối ưu hóa của NVIDIA tốt hơn đáng kể.
Chúng tôi cũng sẽ thử nghiệm quy trình "tạo ảnh video" để xác minh thêm kết quả.

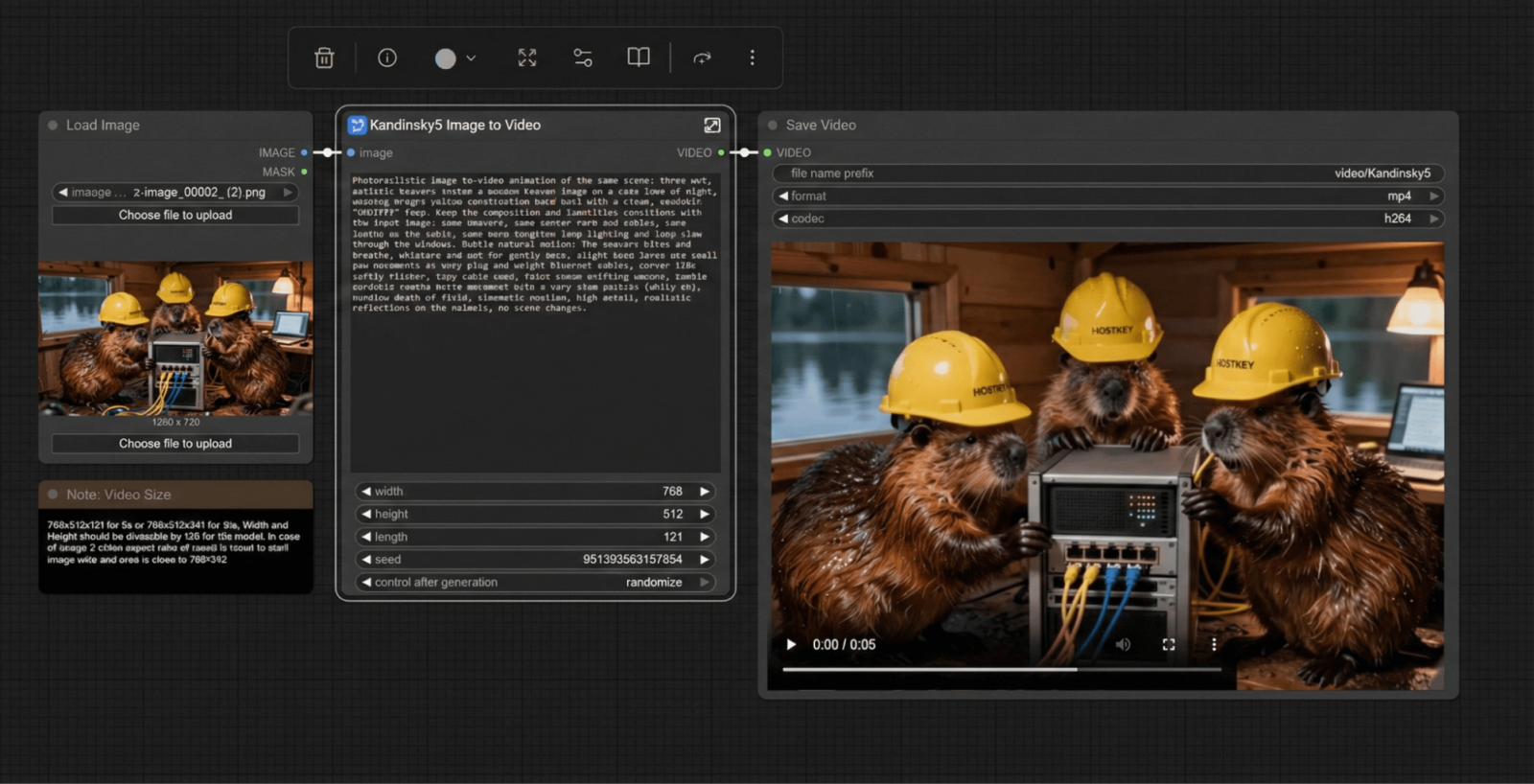
Vậy còn các nhiệm vụ liên quan đến AI thì sao?
Như chúng ta đã biết, AMD định vị RADEON AI PRO R9700 cho các tác vụ liên quan đến trí tuệ nhân tạo (AI). Hơn nữa, kiến trúc công nghệ của AMD được chia thành nhiều thành phần khác nhau, vì vậy việc thử nghiệm card đồ họa này trong cùng các tác vụ dựng hình 3D bằng Blender là rất thú vị. Để dựng hình, AMD sử dụng HIP (Heterogeneous Interface for Portability), tương thích với API CUDA. HIP cung cấp các chức năng cơ bản trong Blender, nhưng hiệu năng của nó không cạnh tranh so với OptiX + RTX Core.
Chúng tôi đã sử dụng liên kết thử nghiệm này https://opendata.blender.org/ để đánh giá. Chỉ có thể chạy thử nghiệm này trên phiên bản LTS của Blender 4.2.
Tổng cộng, card đồ họa này đạt 2957 điểm. Nhìn vào kết quả, nó hoạt động tốt hơn một chút so với RX 6950 XT và tương đương với NVIDIA RTX A4000. Tuy nhiên, nó tụt hậu đáng kể so với Radeon RX 7900 XT dành cho người tiêu dùng ra mắt năm 2022. Cần lưu ý rằng RX 7900 XT có nhiều lõi RT hơn (84 so với 64) và bộ xử lý luồng hơn (5376 so với 4096), cũng như bus rộng hơn. Mặc dù dựa trên thế hệ RDNA3 trước đó, nhưng nó được tối ưu hóa tốt hơn cho việc kết xuất đồ họa 3D.
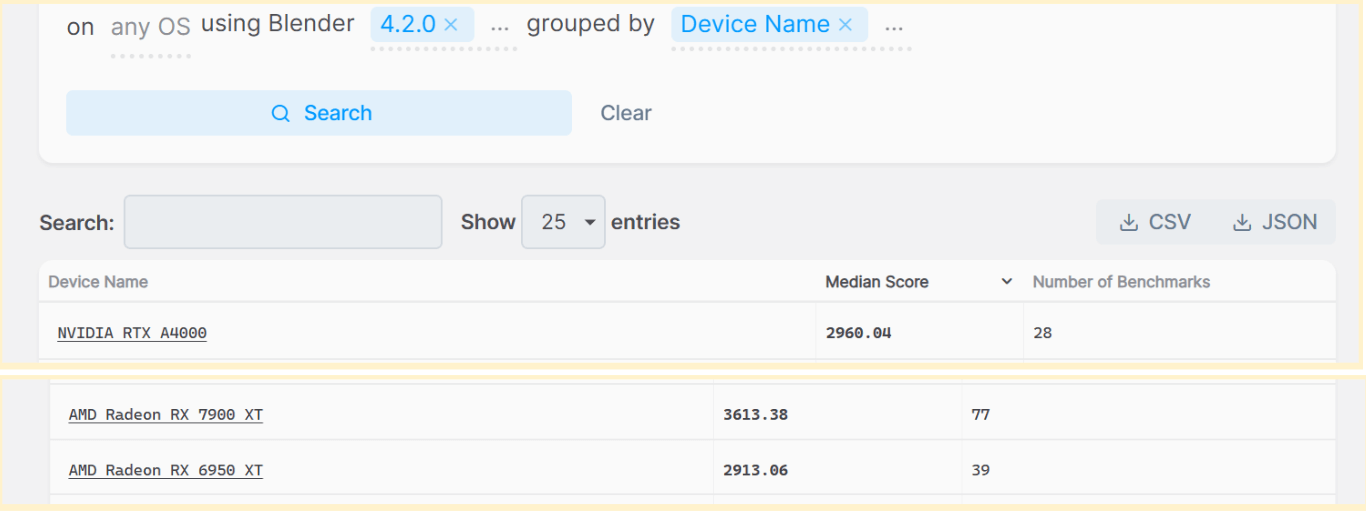
Bản tóm tắt
Kết luận của sự so sánh này khá mơ hồ. Trong khi NVIDIA cung cấp một loạt các card đồ họa chuyên nghiệp được phân loại rõ ràng dựa trên dung lượng bộ nhớ và hiệu năng lõi (như dòng RTX PRO 2000/4000/6000 Blackwell, với mỗi model có thông số kỹ thuật riêng biệt), thì các sản phẩm của AMD dường như không đáp ứng được những sự phân biệt rõ ràng này.
Một mặt, các thư viện và ứng dụng được thiết kế để làm việc với các mô hình mạng thần kinh hoạt động khá ổn định trên card này; khi sử dụng các công cụ như Ollama hoặc VLMM, cũng như llama.cpp, chúng ta thấy hiệu năng tương đương với các card dòng NVIDIA A5000/RTX PRO 4000 Blackwell. Thêm vào đó, card AMD này có dung lượng bộ nhớ lớn hơn (32GB so với 24GB của NVIDIA) và cũng có giá cả phải chăng hơn. Tuy nhiên, nó lại tụt hậu về khả năng tạo và dựng video.
Một vấn đề tiềm ẩn khác phát sinh từ việc hỗ trợ card này trong hệ điều hành: các thành phần nhân và trình điều khiển cần thiết sẽ chỉ có sẵn trong các phiên bản LTS (Hỗ trợ dài hạn) của Ubuntu bắt đầu từ phiên bản 26.04, vào mùa xuân này.
Tóm lại: nếu bạn cần một card đồ họa chuyên nghiệp cho các tác vụ liên quan đến suy luận mô hình văn bản hoặc tạo ảnh với dung lượng bộ nhớ dồi dào, nhưng không muốn trả giá cao cho các dòng card tầm trung đến cao cấp của NVIDIA, thì RADEON AI PRO R9700 là một lựa chọn khả thi. Tuy nhiên, nếu bạn dự định dựng video, đồ họa 3D hoặc thực hiện huấn luyện thêm trên các mô hình, thì bạn nên xem xét kỹ hơn các sản phẩm của "NVIDIA".

13/10/2022

06/06/2024

18/02/2023